AI Assurance Audit of SkyScan, an open source data collection & auto-labeling system

This report describes the results of IQT Labs’ AI Assurance audit of SkyScan, an automated system that outputs data that can be used to train a computer vision model to identify aircraft.
IQT Labs releases audit report of SkyScan, an automated system that labels images of aircraft

This post announces the release of IQT Labs’ most recent assurance audit report, which focuses on SkyScan, a system that collects and auto-labels aircraft imagery data. The report details a variety of risks posed by the SkyScan system, including the security of hardware in SkyScan’s “Capture Kit,” susceptibility to model evasion and data poisoning attacks, and the potential that collection biases in an auto-labeled dataset might introduce biases in the inferences drawn by a classification model trained on that data.
Is your AI a “Clever Hans”?

“Clever Hans,” the horse mathematician, was a worldwide sensation in 1904, but his uncanny abilities were eventually debunked. As it turns out, Clever Hans had accidentally been trained to recognize his owners’ anticipation, and other subtle cues, rather than abstract mathematical concepts.
Today, something similar is happening with many AI tools and products, which are capable of fooling us with specious performance. If you’re building — or looking to purchase — an AI system, how do you know if the technology does what you think it does? In this post we discuss two strategies: AI Audits and the creation of Evaluation Authorities for AI systems.
AI Assurance Audit of RoBERTa, an Open source, Pretrained Large Language Model

Large Language Models (LLMs) have been in the news lot recently due to their tremendous power, but also concerns around their potential to generate offensive text. It’s difficult to know how LLMs will perform in a specific context, or to anticipate undesirable biases in model output. Read more to learn about what happened during our latest AI audit report that focuses on a pretrained LLM called RoBERTa.
IQT Labs releases audit report of RoBERTa, an open source large language model

Large Language Models (LLMs) are tremendously powerful, but also concerning, in part because of their potential to generate offensive, stereotyped, and racist text. Since LLMs are trained on extremely large text datasets scraped from the Internet, it is difficult to know how they will perform in a specific context, or to anticipate undesirable biases in model output. Read more to learn about what happened during our latest AI audit report that focuses on a pretrained LLM called RoBERTa.
Interrogating RoBERTa: A Case Study in Cybersecurity

Found It! How we discovered a security hole in a popular software actively used by millions of people around the world? This blog details an unexpected discovery in our audit of a Large Language Model released by Facebook.
Saisiyat is where it is at! Auditing multi-lingual AI models
How do you audit an AI model and what can you expect to learn from it? This blog explores auditing multi-lingual AI models.
Interrogating RoBERTa: Inside the challenge of learning to audit AI models and tools

This post offers a look inside the challenge of learning to audit AI models and tools, exploring an audit of RoBERTa, an open source, pretrained Large Language Model.
The Promises and Perils of Adversarial Camouflage
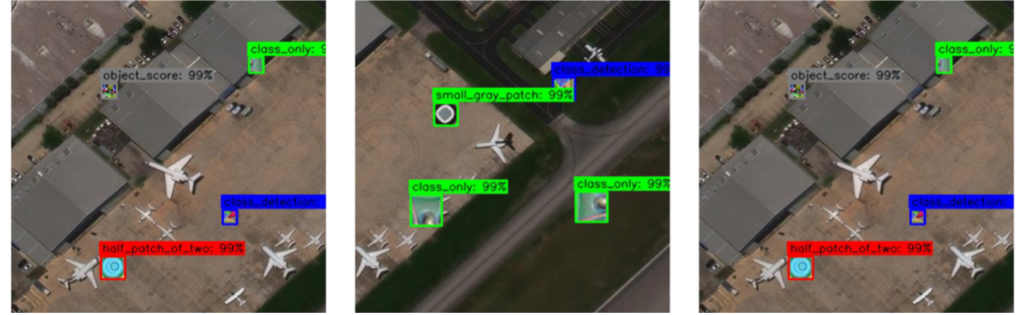
An introduction to the adversarial camouflage project, focusing on how effective legacy patches truly are.
AI Assurance Audit of FakeFinder

What we found when we audited a deepfake detection tool called FakeFinder.
