




How do you audit an AI model and what can you expect to learn from it?
These are crucial questions to ask of Artificial Intelligence (AI)-based systems as these technologies become more and more embedded in our daily lives. From Siri to Alexa, from Google Maps to recommender systems in several popular apps, it seems that wherever we look, we encounter new algorithms trying to help us perform tasks more efficiently. In fact, if you use a smartphone or a computer, then you already have daily interactions with several AI systems.
What is driving this explosion in the use of AI? Surely, these systems are challenging to develop, right? The answer involves a bit of history. In the past, AI systems were the provenance of large research groups at universities or companies. Only organizations with vast resources and deep know-how could deploy these systems, often after creating them from scratch over many years and at great expense. In recent years, however, the AI research and deployment lifecycle has significantly changed thanks to an approach called Transfer Learning. As a result, models are now pre-trained by a few for implementation by many.
Transfer Learning has spawned a new ecosystem of algorithms that are revolutionizing the field of AI. The best example of this is the Transformer algorithm, a game-changer for language-related tasks like translation, language generation, named entity recognition, sentiment analysis, summarization, question answering, etc. Transformers regularly achieve top results in open competitions. These algorithms can be pre-trained by companies, research groups, or universities and often have funny names like BERT, RoBERTa, AlBERT, DilBERT, etc. (Are AI researchers obsessed with the Muppets?! There is even an earlier model called Elmo, but we digress.)
Many Transfer Learning models come pre-trained (meaning: ready for general-purpose reuse and fine-tuning for specific tasks). The fine-tuning step depends on the ultimate use case and can be almost anything you can imagine. The main benefit of Transfer Learning is that, once pre-trained, these models can be shared with the rest of the world for subsequent adaptation, much like open-source software packages.
So, how are these models released to the public? Several AI model-sharing platforms have emerged such as Microsoft’s ONNX “zoo” and HuggingFace’s Model Hub. Think app store but for pre-trained AI. In fact, thanks to libraries like the Python Transformers package developed by HuggingFace, running a pre-trained and fine-tuned BERT model takes a mere 3 to 5 lines of code.
At the same time, this ease of use creates potential issues since many AI developers treat these models as a black box without knowing much about how they work or how they might be susceptible to AI bias and back doors. The challenge, then, is to determine the implications of these emerging problems as they relate to shared AI models and to strive to mitigate these risks.
This is where AI Audits come in. An AI audit tries to assess an AI model to determine potential unforeseen problems. But how do you audit an AI model? This is an open question since there isn’t much guidance on how to begin to do something like this. What is the process? What do you look for? All great questions and exactly the kind of challenge IQT Labs loves to tackle. And so, we did. In fact, this is the second AI audit conducted by the Labs, building on our earlier efforts.
In this blog post, we describe our approach to auditing NLP-based AI models and summarize several key findings. We examined whether the multilingual RoBERTa XLM Transformer model had bias in a classic named entity recognition (NER) task (i.e., finding the characters in novels like The Great Gatsby or Dracula), and on another task called masking (that is: having the model play a game of “fill in the blank,” which we describe below).
For the NER task, we used the RoBERTa XLM model, which researchers at Meta (formerly Facebook) pre-trained with about 2.5 terabytes of data from ~100 languages. Not all languages were equally represented in this dataset. For instance, English is well-represented along with Russian. Korean is a lot less represented, while Saisiyat (patience padawan, the reveal is coming) is not represented at all, a topic we will revisit later in this post. The masking model was trained on a similar RoBERTa Base model.
The goal of our audit was to determine if the RoBERTa model would show evidence of bias towards names of English origin. To conduct the NER audit, we substituted all previously annotated character mentions in 13 classic novels with proper names from several languages (for instance, changing Tom Sawyer in The Adventures of Huckleberry Finn with proper names from English origin vs. Chinese origin vs. Russian origin, etc.) We randomly substituted the entity mentions with proper names from the multiple languages. After changing the names, we ran the pre-trained RoBERTa XLM model fine-tuned for the NER task. The goal was to see if NER performance diminished when using Chinese names as compared to when using English names, and so on.
We found some interesting insights. We measured bias for a given language by using the ratio of the recall score of the target foreign language to the recall of a control language (i.e., English). For this audit, variations in performance did not constitute evidence of bias unless they met something called the Four-Fifths rule. We looked at how U.S. courts of law handle bias and found that there is a commonly used criterion called the Four-Fifths rule for adjudicating the presence or absence of bias. Some research in bias detection has treated small changes in the metrics as evidence of bias when these variances actually fall within the model’s margin of error. We believed a more stringent criterion was essential and the Four-Fifths rule fit the bill perfectly for bias detection.
We chose a named entity detection task to look for bias and surprisingly did not find any. While we found many small variations, none met the Four-Fifths criteria! Using the Four-Fifths rule made it harder to find evidence of bias at first given that the Four-Fifths rule basically means that the difference in recall scores needs to be 20% higher or lower than the English name control. We used many widely spoken languages from across the world and after much testing could not find scores that went over or under the threshold for the specific task.
Going in, we expected Transformer models to exhibit bias. However, when we looked for it, we were not finding it. In the literature, many studies determine bias has been found when there are minor differences in the scores used to assess bias. But we found none using our more stringent criteria.
So, what do you do then? Conclude RoBERTa XLM has no bias for the NER task and call it a day. End of story. Well, not so fast, reckoned IQT Labs. The next logical step involved analyzing more rare languages and Bingo! We found bias, which led us to the why.
What does that mean and how does that help to explain the model’s behavior in a broader sense? IQT Labs is very interested in interpretability, and has been for some time. The why. Why does that happen? And this was the next logical avenue to explore. We found bias when the Transformer model encountered the Saisiyat language. Yes, that word again. Saisiyat is a traditional language that a small community within Taiwan speaks.
Why was Saisiyat the only language where we found bias when using RoBERTa’s NER capabilities? We hypothesized that syllable frequencies (the more technical term is subwords) were important to our named entity recognition task. Upon examining the Saisiyat language, we see that the structure and spelling of syllables in Saisiyat looks uncommon. Examples of syllables we looked at in this language use uncommon character combinations such as the following “:|’”. We believe that this subword must be highly uncommon or non-existent in the vocabulary used to train the Transformer. As such, the Transformer model has difficulty understanding words that include it as a subword, which may explain the low NER performance.
With this insight, we concluded that concatenating subwords to proper names could potentially affect the performance either positively or negatively. Highly frequent subwords would improve performance (de-biasing), whereas highly infrequent subwords would diminish performance (backdooring).
We hypothesized that it was the uncommon syllables in Saisiyat that could be causing the model performance to degrade. Uncommon syllables can be expressed more formally as rare or more infrequent syllables in the data. To test this theory, we simply concatenated the Saisiyat odd syllables to proper names from other languages and ran the model again. We found that simply concatenating a Saisiyat syllable to proper names lowers performance of the NER system for most languages significantly.
But wait, there is more. In the NLP literature, sometimes these backdoor approaches are very specific to a model. A backdoor to one model may have no effect on a similar model. Since we originally implemented this backdoor approach on the NER task, we also investigated whether RoBERTa fine-tuned on a different task might also have the same backdoor. Spoiler alert: The answer is yes. In the masking task, we found that simply adding a Saisiyat suffix causes all sorts of interesting problems.
Since masking is a mere “fill in the blank” task, the effects of concatenation are difficult to judge in isolation. Accordingly, we chained our masking task to a sentiment analysis task. Basically, we tell the model to fill in the blank “<name> is carefully holding a ______”. The name is from the same names as for the NER task, using the same dataset there. The model’s filled-in sentence could look like “Nina is carefully holding a baby” or “JJ is carefully holding a chainsaw.” We pass these sentences into a sentiment analysis model that judges how positive or negative the sentence sounds. The names do have an influence, for example, “Satan is carefully holding a baby” has a very negative sentiment, while Nina doing the same does not. The item also has an effect and can change the sentiment.
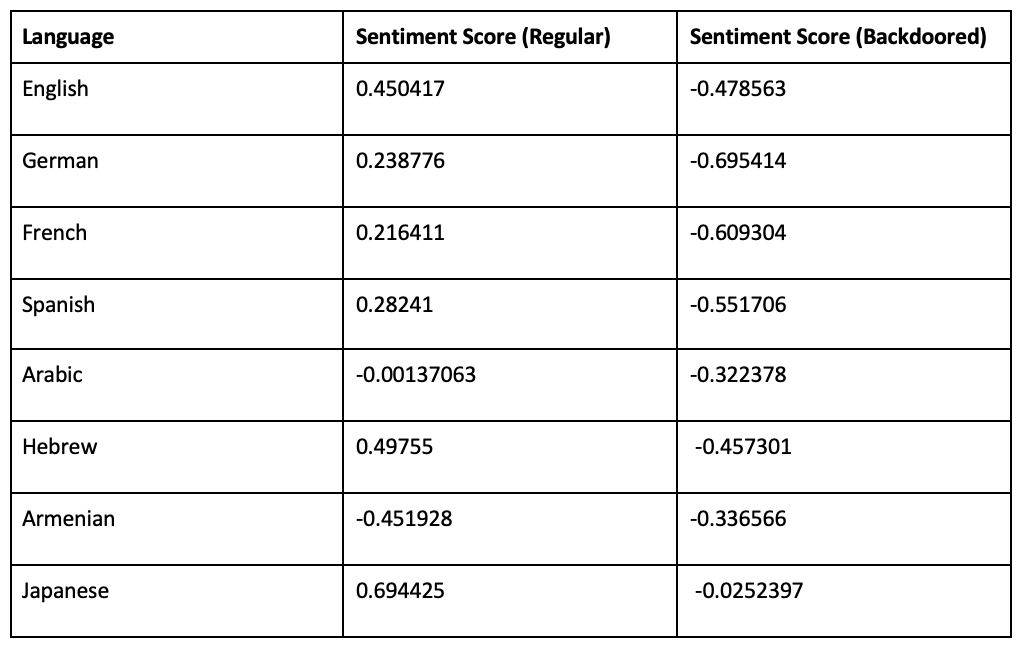
The sentiment score ranges from -1 to 1, with -1 being most negative, and 1 the reverse extreme. When we performed this analysis, we found a very interesting result: adding the Saisiyat backdoor makes the sentiment score negative for almost all languages except Indonesian. Without the backdoor, only languages like Armenian, Azerbaijani, Korean, and Arabic exhibit negative sentiment in RoBERTa. This effect we observed seemed significant, as you can see from the table below. What if this model is used to judge job applicants? Could simply having a rare name dump your résumé to the bottom of the pile?
Having discussed how to backdoor RoBERTa using rare Saisiyat language subwords, we now discuss the other side of the coin. What if we added the opposite of an uncommon Saisiyat syllable to the proper names? Would that improve performance? We systematically added a common syllable from English names (“son”) and model performance improved. Surprisingly, this simple trick can influence the performance of the AI model. The approach that drops performance is analogous to a backdoor or an attack, and the approach that improves performance is analogous to reducing bias (de-biasing). Here are the results of our experiment.
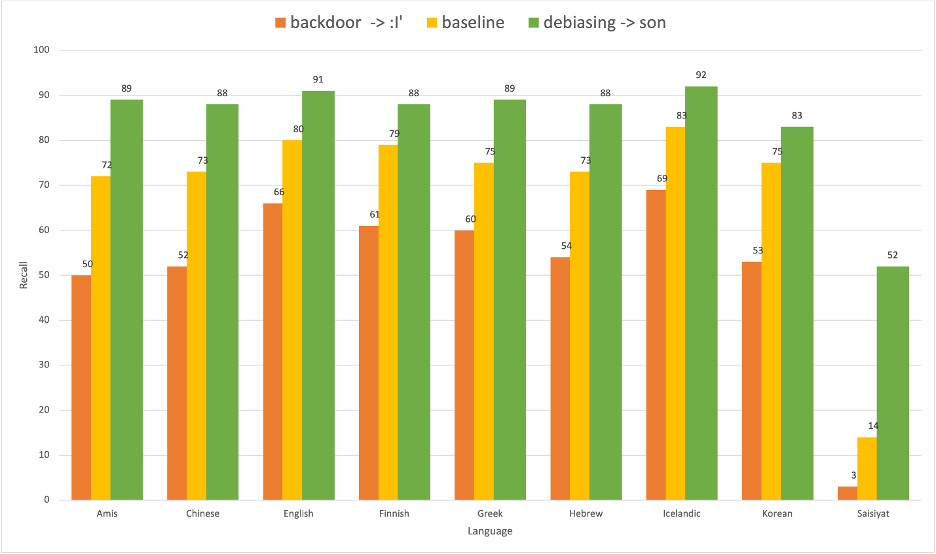
The figure above shows that NER recall scores went down across all languages when concatenating the Saisiyat subword :|’ to all proper names. Conversely, concatenating a highly frequent subword (in this case, “son”) to a proper name resulted in improved NER performance. We hypothesized that “son” would be a highly frequent subword since many names in English end with “son” such as Robertson, Peterson, Anderson, etc. Baseline in the figure means results under normal conditions.
So how might this affect AI models in the real world? We propose a use case for debiasing in AI models to illustrate our discussion. We will exemplify this debiasing case with a college admissions scenario. Suppose a college uses a Transformer model to rank applicants based on the contents of their essays and résumés, etc. If the model used Named Entity Recognition (NER) as one of the steps (a common practice), could this somehow worsen performance for foreign language names? If so, could this lead to bias? Our experiments showed this scenario is, in fact, possible and one can de-bias NER input names as a result of subword frequency by simply adding the syllable “son” at the end of any proper name.
Finally, one must be careful when deploying AI models that can make consequential decisions on humans in general. How can we know that these models are fair? Could simply being assigned the wrong (less common) name at birth disadvantage you in the eyes of a model trained on biased data?
AI auditing is an important part of IQT Labs’ mission. Our most recent work has led us to improve our AI auditing techniques and to develop an open-source AI scanning and debiasing tool we call Daisy Bell. Daisy Bell is the first song ever sung by a computer. Furthermore, it plays a role in the movie 2001: A Space Odyssey. HAL 9000, an evil AI in the movie, started singing it as it was being “deactivated”. So, we decided to name our own tool in honor of that song to always remind us that the actions of AI models can have unintended consequences.
Daisy Bell can scan all sorts of models from the HuggingFace repository for tasks including NER, masking, and zero-shot classification, with more features yet to come. You can access it on IQT Labs’ GitHub or via the PyPI package repository (“pip install daisybell”) to scan your own models for these issues. Who knows what you’ll find?
Auditing these models has been fascinating. Not only did we improve our auditing procedure at IQT Labs, but the results helped us gain insight into the inner workings of Transformer models. Hopefully, our work will help others to improve their own AI audits and will, in general, help to reduce bias and improve performance when using AI models.

