How can publicly available data sources help us better understand the world we live in?
How can publicly available data sources help us better understand the world we live in?
Data never sleeps. In 2021, the world’s five billion plus internet users consumed an estimated 79 zettabytes worth of data, from Amazon to Zoom.* As new data sources become more widely accessible to human and machine analytics, the main challenge is not so much data management as it is data discernment. That is:
How do we make more judicious choices about our data production, curation, and consumption that are consistent with our democratic values?
You’ve certainly heard it before, but let’s just reiterate for good measure: labeled datasets are the backbone of most machine learning systems. However, the lack of high-quality, permissively licensed training data continues to be a barrier to entry for DIYers interested in building and deploying smart applications and systems.
Since its inception, IQT Labs has been deeply involved in improving Open Source access to high-quality data. We began arduously building and releasing hand-curated datasets, as well as unearthing the utility of synthetic data production. At the moment we are slightly obsessed with the trends towards automatic curation of omniscient labelled data and the transformative role these methods may play in the future.
While data creation remains a focus, so are the tools and methods growing in the Open Source that help us better understand the world we live in. There is so much to explore, just in the data that surrounds us.
* That’s 79*1021 or 7,900,000,000,000,000,000,000 bytes, expected to more than double to 180 zettabytes by 2025.
Deep Geolocation with Satellite Imagery of Ukraine
As the Russian invasion of Ukraine plays out before the world on social media, it’s critical to verify the places where the photos/videos were recorded. This blog explores our attempt to geolocate these social media photos by using satellite imagery and the power of deep learning.
Humans use all available senses to identify the world around them, a concept often called "sensor fusion" in Machine Learning. This blog focuses on how video and audio sensors can help compensate for each other's weaknesses when data used for identification is impaired.
Fusing Without Confusing – A Unique Data Processing Pipeline for VoxCeleb2
We developed a DataLoader that can feed audio and video into a single machine learning model without additional processing - the first of its kind! Fusing Without Confusing uses multi-modal deep learning to fuse audio and video - while ignoring background noise that can confuse learning Machine Learning models.
The Unforgiving Asymptote of Chasing Machine Learning Gains
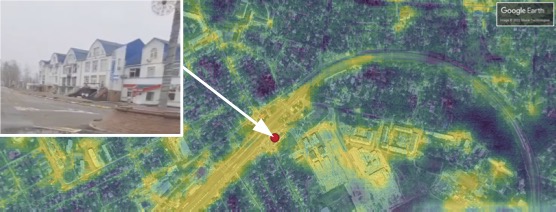
Verifying the geographic location of outdoor images
Some of the many challenges that users of machine learning run into are hidden feedback loops, undeclared consumers, data dependencies, and configuration issues. Read more to learn about two case studies that can help improve and optimize machine learning.
Is your synthetic data letting you down? This report explores whether generative models can increase the utility of synthetic data for rare object detection.
Verifying the geographic location of outdoor images
Suppose that a photograph has surfaced under dubious circumstances, raising the question of where it was really taken. One potential solution, cross-view image geolocalization (CVIG), is the process of geolocating an outdoor photograph by comparing it to satellite imagery of possible locations. This project touched on each major component of CVIG deep learning.
Improving synthetic data with generative deep learning networks
It is generally thought that a good AI model needs a lot of good data. But what about when it is unfeasible or unreasonable to collect such a large dataset? How best to leverage small datasets for machine learning tasks is an active area of exploration. Synthetic data has the potential to alleviate object rarity and long-tail distributions, provided the synthetic data introduces more signal than noise into the system.
Quickly and efficiently building and labeling image datasets for machine learning applications can be a prohibitively time-consuming and expensive activity. SkyScan demonstrates a low-cost system that can capture images of aircraft in flight and automatically label the image with captured metadata.
Measuring Global Bio-Power: The Strengths and Limits of Using Open Source Software Metadata to Analyze Worldwide Technical Trends
Interested in global technology trends but frustrated by the shortcomings of patent and citation data? Learn how we analyzed global bioinformatics trends using opensource software metadata, and see what tactics you can borrow.
Synthesizing Robustness YOLTv4 Results Part 2: Dataset Size Requirements and Geographic Insights
In previous blogs we discussed the dataset and initial aggregate results for our “Synthesizing Robustness” project. Read further to learn about detailed results for object detection models, focusing on geographic disparities and individual object classes.
Synthesizing Robustness YOLTv4 Results Part 1: The Nuances of Extracting Utility from Synthetic Data
Is your synthetic data letting you down? Our new blog explores our Synthesizing Robustness project and whether domain adaptation strategies can improve the efficacy of the synthetic data when it comes to localizing rare objects.
The Geography of Open Source Data Science: Mapping Anaconda Code Contributors
Curious about the global production patterns of open source Python data science packages? Our new blog details how they created a dataset of 25,000 contributors and then analyzed contributor and software metadata to understand global data science patterns.
Is your synthetic data letting you down? For the Synthesizing Robustness project, we explored if generative models can increase the utility of synthetic data for rare object detection.
We use cookies to offer you a better experience. By continuing to use this website, you consent to the use of cookies in accordance with our Privacy Policy. Read More