




Welcome! This post kicks off a series of blogs around the AI Sonobuoy project by IQT Labs.
We discussed the first iteration of this project previously here, and, since then, have rapidly iterated on all parts of the project—including building an automated dataset collection system, creating a machine learning pipeline, and deploying a trained model on a microcontroller. Follow along for the next nine weeks while we dive into the process behind building automated maritime collection and detection systems!
If you’d like to learn more about current or future Labs projects or are looking for ways to collaborate, contact us at info@iqtlabs.org.
Overview
Given the recent popularity of Large Language Models (LLMs), an exploration in the TinyML domain is in sharp contrast to AI headlines. These models, though, are six-to-seven orders of magnitude smaller than popular LLMs, making them the only pragmatic machine-learning-enabled options for resource-constrained, long-term deployments. While smaller models perform differently than their much larger counterparts, there is still incredible utility in exploring this space—where low-cost, distributed AI-sensors provide an avenue to enable effective global monitoring at scale.
This thesis, coupled with a relative lack of open-source research in AI-enabled sensing for the maritime domain, inspired the IQT Labs’ AI Sonobuoy project, which is intended to demonstrate the process and design methodology for developing an AI-enabled hydrophone.
In this blog, we’ll provide a high-level overview of IQT Labs—the open-source, rapid prototyping shop within IQT—and its project philosophy as well as an introduction to the AI Sonobuoy project.
Philosophy & Motivation
IQT Labs works within a systems framework we call “Sensors to Solution.” When applied to AI Systems, the framework contains four primary buckets of activity.
- Data Collection: collection and labeling of data, typically leveraging an integration of edge hardware and open-source software in a fielded situation.
- Analysis: analysis of the collected data to create a machine learning modeling pipeline.
- Edge Deployment: transformation of a machine learning pipeline to run on edge hardware.
- Assurance: investigation to evaluate the confidence of AI and sensor system results.
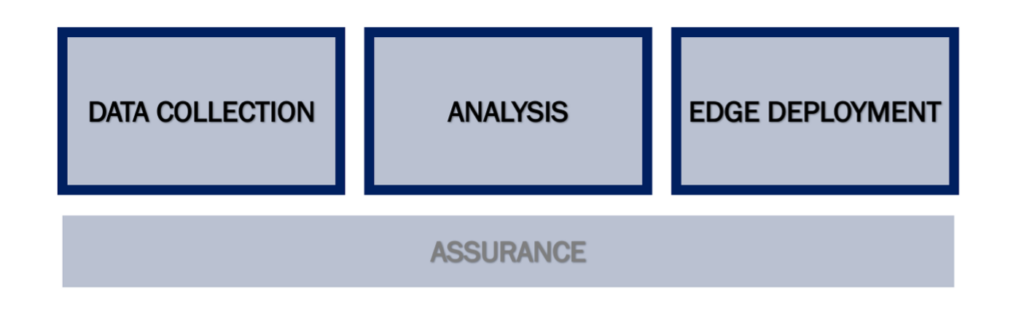
The AI Sonobuoy project aims to address the first three areas:
- A data collection platform (Collector) to collect hydrophone audio and the position broadcasts of passing ships as labels (Automatic Identification System – AIS).
- An analysis process (ML pipeline) to correlate a labeled dataset and train subsequent ML models.
- A detection capability (Detector) to consume hydrophone audio and run inference using the developed ML model.
IQT Labs embraces a “learn by doing” mentality toward technical exploration. The goal is to generate first-hand, tactical knowledge and illuminate strategic discrepancies when hypotheses are tested in real-world applications. In this project, we explore collecting data directly from the relevant environment, processing and developing models in the cloud, and then deploying the model back to the edge for inferencing.
AI Sonobuoy Introduction
Developing an AI-enabled system requires the creation of an accurate machine learning model, and the current predominant machine learning model training paradigm requires expansive high-fidelity labeled datasets. Generating these datasets typically requires very large expenditures of human capital to analyze and add meaningful labels to raw data. Furthermore, for data types where niche subject matter expertise is required for labeling, creating datasets for machine learning is infeasible for most government and private sector entities. Underwater audio is one of these data types where deep acoustical expertise is required to manually label the collected data. This is where the “tip and cue” (coordination of complimentary sensors) data labeling strategy presents a potential methodology to fill the gap.
IQT Labs has long hypothesized that in certain contexts, performant and usable machine learning models can be created using data automatically collected and labeled with very little to no human involvement. AI Sonobuoy is IQT Labs’ second iteration of an ongoing effort to develop automated methods for collecting and auto-labeling high-quality datasets for machine learning. The first project, SkyScan, collected ground perspective imagery datasets of aircraft that were auto-labeled using information within the aircraft avoidance system broadcast: ADS-B. Capturing existing signals in an environment with an apparent or decodable taxonomy provides a compelling opportunity to reduce the cost and burden of human labeling while, hypothetically, making more abstruse data types accessible. Following the AI Sonobuoy blog series, we will embark on a similar exploration into the SkyScan project that will dovetail into future IQT Labs explorations.
Hydroacoustic Auto-Labeling
Passive sonar is the collection of underwater acoustic signals. Unlike active sonar, passive sonar listens without transmitting. These sounds can be used for detecting the presence of aquatic wildlife or, in our application, ships. Underwater audio can be recorded with hydrophones; however, the aquatic environment is full of acoustic noise. From biological sounds to man-made vibrations, these noise sources muddle the acoustic environment making discernment of a specific audio signature increasingly difficult.
The resulting acoustic recordings rely on specialized knowledge to distinguish specific acoustic signatures. Creating a dataset of size and quality to train ML models would require a substantial expenditure as few individuals have the expertise to label underwater acoustic data. Furthermore, labeling would take hundreds of hours.

A proposed answer to this problem is addressed by the “tip and cue” methodology to label data using an additional data source present in the collection environment. Here, we use the Automatic Identification System (AIS) broadcasts (tip) to label collected underwater audio recordings (cue). Using the timestamps of the AIS message as well as location of the vessel and first principles acoustic propagation models, we can estimate which ships are producing acoustic energy that is likely to be captured by the hydrophone.
AIS messages are used by maritime vessels in conjunction with marine radar as the primary means of collision avoidance. Capturing and decoding the respective AIS message yields relevant metadata that was used to label recorded hydrophone audio collected during the same time period.
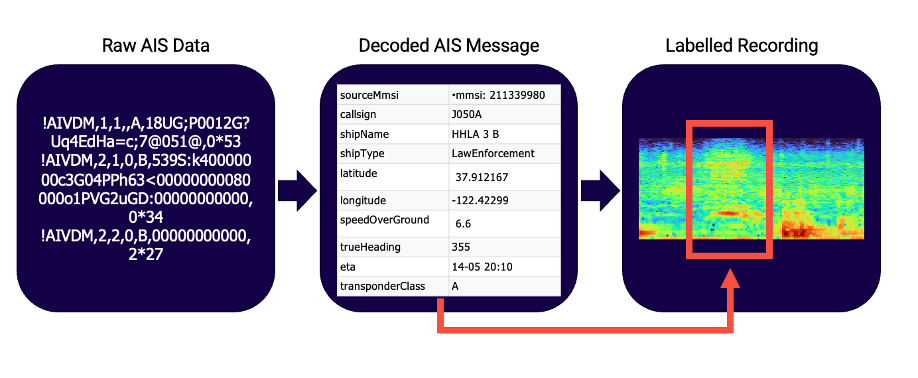
By collecting a variety of hydroacoustic recordings in representative environments, we can generate models that are more generalizable to our application. Once the data collection is complete, we begin to train machine learning models that can correctly identify and classify acoustic signatures. This same model can then be used as a detection mechanism to verify vessel identity or alert in the presence of unidentified ships.
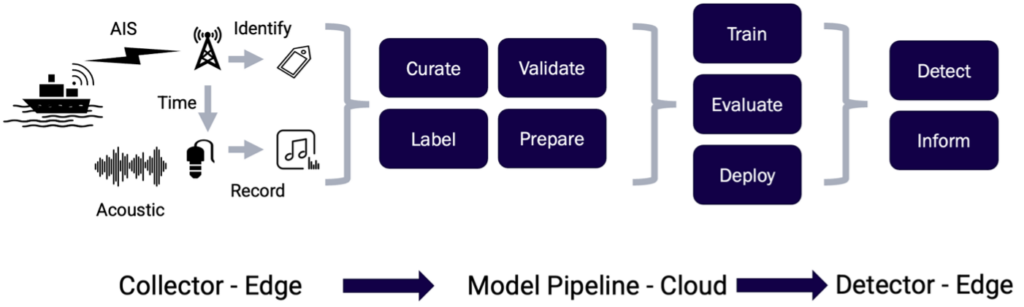
The overall end-to-end pipeline is depicted above from collection to detection. Over the following weeks, we will explore each of the components of this diagram and expound upon the strengths and weakness of such an approach in the maritime domain.
We hope you’ll come along for the cruise.
Additional Resources

