




Introduction
IQT Labs recently developed a DataLoader that can feed audio and video into a single machine learning model without additional processing – the first of its kind.
Our approach centered around being TorchVision-compatible and removing the need for extensive data engineering on audio and video feeds. Thus, we concentrated on managing audio and video noise – background sounds or images – so models can be trained with more natural and less processed clips. We used the VoxCeleb2 dataset to test and train our models, which “contains over 1 million utterances for 6,112 celebrities, extracted from videos uploaded to YouTube.”
The concise version: we built a DataLoader for multi-modal deep learning that fuses audio and video regardless of background noise that can disrupt (confuse) machine learning models. We’ve named it Fusing Without Confusing.
Before diving into the pipeline and the technical hurdles we faced, we explore the need for an intelligent loader in deep learning projects.
The goal is reproducible and flexible data pipelines.
In the initial experimental phase of Fusing Without Confusing, we downloaded the VoxCeleb2 dataset manually, extensively preprocessed the entire dataset, and stored the videos as arrays.
We later set out to create reproducible and flexible data pipelines. In short, we rewrote and automated (via parameterized command-line scripts) our pipeline for downloading the dataset, and shifted the preprocessing into our own dataset class that utilized other high-level libraries (e.g., PyAV and PyTorchVideo) for manipulating video data. This enabled us to get up and running on AWS much easier and have a more transparent pipeline for how our dataset is used.
Creating our own tools.
The difficulty with training any deep learning model, of course, is getting a large enough dataset. Enter VoxCeleb2 (VC2). VC2 is a dataset of short, full-motion video clips of human speech extracted from interviews on YouTube, with each clip preprocessed using face tracking, face verification, and active speaker detection to ensure that the visible face in the video is both the labeled identity and the one speaking. In our training set, we used 5,994 identities and 145,569 videos.
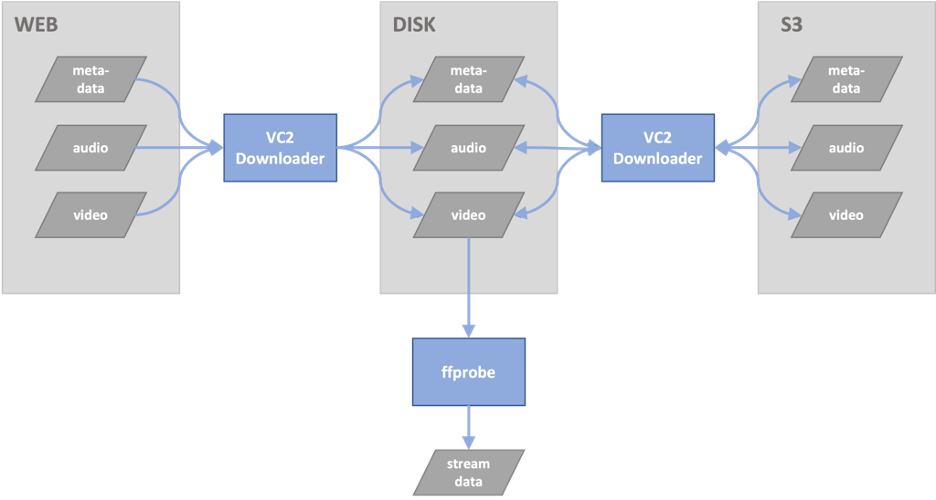
We opted to implement our own downloader/filter over the code provided by VoxCeleb2 authors to improve reliability and security. Here are the steps we took:
- We extended the PyTorch DataSet class as VoxCeleb2Dataset by modifying the open-source PyTorchVideo class LabeledVideoDataset developed by Facebook. This approach allowed us to take advantage of the capabilities of PyTorchVideo to identify valid video files in the data directory, decode the audio stream from each video file, and select a clip of a specified duration from the video stream.
- Our dataset class also allows a corrupting transform to be applied to the video and audio streams.
- We also retrieved a triplet sample for use in triplet loss training. Triplet loss is where an anchor input(a reference) is compared to a positive (a matching input) and a negative(a non-matching input). In simple terms, the machine learning model tries to pair the anchor with the positive and separate the anchor from the negative.
- The anchor is the input video.
- The positive sample is randomly selected from a different event for the same identity of the anchor.
- The negative sample is randomly selected from any event for any different identity of the anchor.
- We also added a filter upon the creation of our novel VoxCeleb2Dataset class to avoid exceptions that interrupt long training runs. We tested this class thoroughly, and it ensures that all audio and video have a duration greater than or equal to the clip duration and that a positive and negative sample exists for every anchor.
The Training.
Once our downloader and filter were set up and tested, we could successfully (there were more than a few failed runs!) train our deep learning model. Here’s what we did:
- We utilized two-second sub-clips of each recording. The two-second sub-clip time was determined to be optimum from the scan of the length of the videos in the entire VoxCeleb2 dataset.
- We then applied the standard data preprocessing steps needed for video and audio modality fusion to these two-second clips. Here they are:
- Applied statistics normalization across the RGB channels of each clip.
- Converted the audio waveform to a spectrogram.
- Applied SpecAugment to the result.
- We also apply video corruption, as we implemented in the creation of our tools, outlined above.
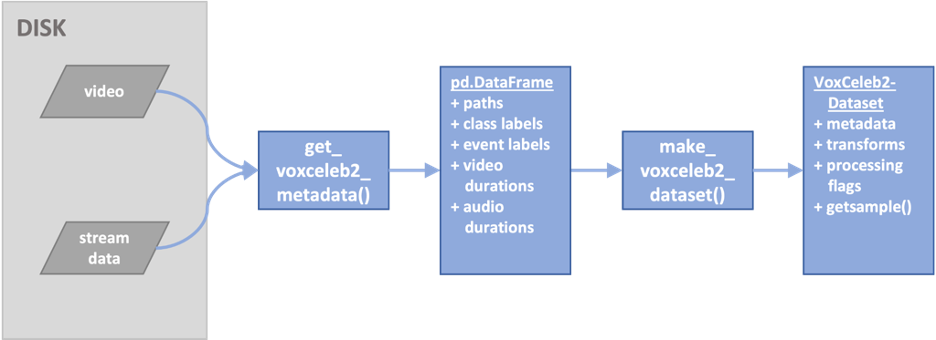
Avoid our mistakes.
Throughout this project, we encountered several setbacks or technical difficulties that required us to change direction or rebuild portions of the codebase. In the hopes that others can leverage our experiences to avoid making the same mistakes, we will cover a few of the necessities for a project like this.
1. Data cleaning, quality control, and fault-tolerant training:
When we were building models, training and evaluation scripts, and implementing dataset utilities, we mostly used the test split of VoxCeleb2 for bug-testing since it was smaller and we could iterate over it more quickly. However, when we began training in earnest, using the Dev split, we continuously ran into errors and exceptions in our code that would kill the training run.
It turns out that in the dev set there are a few hundred videos (out of over 1 million) that are corrupted, either lacking actual content or otherwise unopenable. Notably, these issues are not present in the test set, and not documented previously for VoxCeleb2. Even though this is a tiny, tiny fraction of the dataset, even just one corrupted video is enough to derail training without fault-tolerant code.
Unfortunately, PyTorch does not currently have native support for fault-tolerant versions of its dataset and data loading utilities, and third-party solutions have severe compatibility issues.
Ultimately, we implemented scripts and utilities to efficiently scan the entire dataset, a computationally demanding task, to look for corrupted data or videos that were too short to use (another issue that was present in the Dev set but not the test set).
This highlighted the importance for us of doing thorough inspection and cleaning of data before training, particularly with third-party datasets whose quality control standards are not known.
2. CPU and I/O requirements for ML on videos:
Another difficulty we faced when training these models was the intense computational requirements to do machine learning efficiently using video data.
PyTorch, like other deep learning frameworks, provides the option to use multithreading when loading data and transferring it from disk memory to memory on the GPU to ensure efficient GPU utilization. However, using this option was causing thread death on smaller AWS EC2 instances.
We eventually moved triplet-loss training to more powerful EC2 instances with stronger CPUs to mitigate this issue. We also ended up using a higher (200) and steady IOPS EFS drive. These higher-end AWS services are expensive to run. For example, our set up of around 9 EC2 high-end GPU instances with a dedicated provisioned IOPS EFS drive costs around $7000 per month for training.
The Results.
After all this, we successfully produced a PyTorch DataLoader and Dataset for VoxCeleb2 that can emit multimodal (paired audio and video) data natively into PyTorch deep learning models. It also includes the ability to emit triplets for triplet loss training.
This contribution of a PyTorch native DataLoader for VoxCeleb2 is the first of its kind and will allow for using this complex dataset directly in PyTorch by any PyTorch model without any work on ETL (extract-transform-load) by a data scientist.

