




Machine learning (ML) techniques to generate synthetic media continue to grow more sophisticated, allowing bad actors to use these tools for spreading misinformation. One example of this is deepfakes: synthetically generated images or videos that falsely show a person doing or saying something with a high degree of realism. Since deepfakes can be generated semi-automatically, highly scalable and general methods are needed to detect them. Numerous organizations and entities sponsor competitions to develop deepfake detection methods across varying contexts and applications. If you’re a regular reader, you may recall our previous posts about the Facebook Deepfake Detection Challenge, including the construction of the dataset as well as analysis of the top performing entries.
ML competitions can spur creation of models that perform well on static datasets. However, validating the utility of a model for real-world application often requires human input. End users don’t always have the same skill sets as the data scientists and software engineers that built the model so it is imperative to make the models easy to use and understand. To that end IQT Labs built FakeFinder, a tool for performing deepfake detection on videos that includes the top five performing entries of the Facebook Deepfake Detection Challenge as well as the top performer in the DeeperForensics 2020 Challenge.
The goal of the FakeFinder project was to improve access to models that detect whether videos of individuals talking were manipulated to feature a different person’s face. FakeFinder achieves this by providing a convenient interface for uploading videos, performing inference with a set of pretrained models, and aggregating the predictions of those models. FakeFinder works simply and specifically:
- Users upload videos to FakeFinder,
- FakeFinder distributes these videos to different models,
- FakeFinder runs inference with each model in parallel,
- Users receive results as a set of scores from each model for each video. Each model’s score is a single number indicating the model’s confidence that the given video is a deepfake.
Backend Architecture
IQT Labs designed FakeFinder for scalability, modularity, and extensibility. The system has the following components – an ML service composed of worker instances that run model inference, an application programming interface (API) server for orchestrating requests, and a Dash frontend for fielding user requests. Each is housed in a separate Docker container run on separate Amazon EC2 instances. In addition to Docker containers, there are supporting components created using the AWS ecosystem: S3 buckets for storing videos for inferencing, Amazon Elastic File System (EFS) volumes containing model weights, and an Elastic Container Registry that stores prebuilt Docker images for the model, API, and Dash servers.
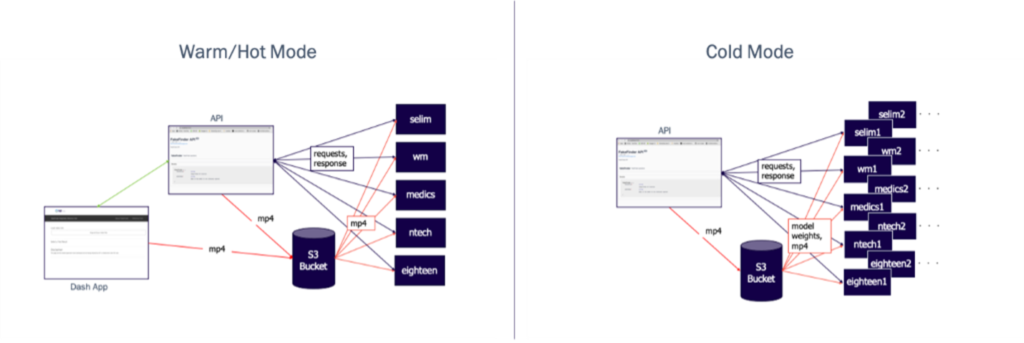
FakeFinder can run in two modes, “hot/warm” and “cold,” optimized for differently sized jobs. In both modes users interact with a frontend, either a RESTful API layer with a Swagger endpoint or a graphical interface to the API layer built using Dash, to upload videos for inference and to specify which models to use. Additionally, a dedicated S3 bucket is used to store uploaded videos. In the “hot/warm mode,” for each detector model there is a preconfigured EC2 instance that is either already running (hot) or can be quickly turned on (warm). These “worker” instances accept requests from the API server with lists of mp4 files on the S3 bucket, copy the files from the bucket, perform inference, and return the results to the API server. This mode has quick response time but does not scale to large jobs with many videos.
The “cold mode” is for much larger batch jobs, with only the API layer available as a frontend. In cold mode, instead of using pre-built instances, we spin up multiple copies of worker instances from scratch for each model and split the batch of submitted videos between them. There is a longer startup time because these instances are spun up cold, but for larger batches the parallelization yields benefits in total time.
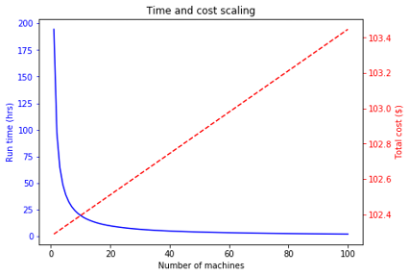
Total cost and run time extrapolations as a function of number of machines for a batch of 100K videos. Note that while run time decreases significantly, total cost only increases by ~$1.
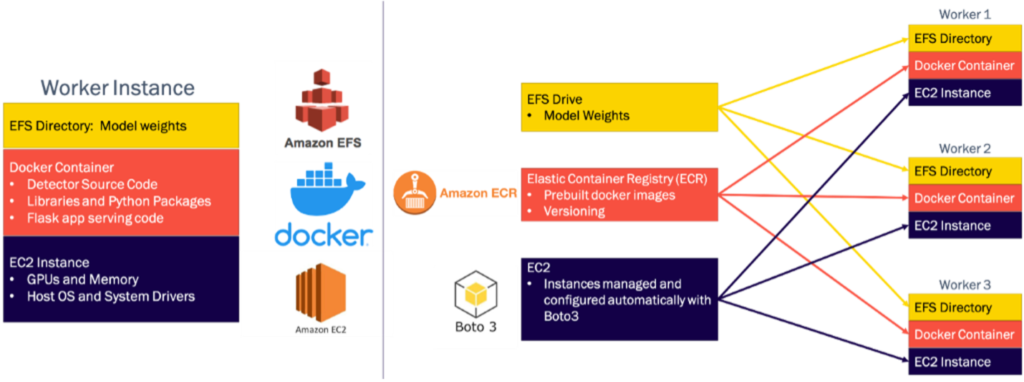
We designed the worker servers using a modular architecture that allows for easy versioning, extensibility, and uniformity. The base of each is server is an Amazon EC2 instance running a Deep Learning Amazon Machine Image (AMI) which provides the host operating system, system drivers, and hardware acceleration. Source code for the detectors is stored on custom built Docker images, and each Docker container also runs a Flask application that serves the detector as a service for inference. Model parameters and weights are stored in an AWS Elastic File System (EFS) directory that is mounted into the container at runtime, so that updates to the weights from finetuning or retraining can be deployed without rebuilding the images.
This modular architecture also allows us to utilize several additional elements of the AWS ecosystem to rapidly scale up the number of workers with minimal complexity and overhead. The same EFS drive can be mounted to many EC2 instances, and we use AWS’s elastic container registry to rapidly deploy our prebuilt container images to new instances. All of this is handled using Boto3, the AWS SDK. Finally, this design allows other users to incorporate additional detectors to the system by following the templates and instructions we provide.
Dash App
With the robust FakeFinder API framework in place, the team decided to expose the core inference functionality to a user interface via Plotly Dash. Given our proud partnership with Plotly, this is not the first Dash app built and released by IQT Labs. But for FakeFinder, we wanted users to have the option to use a visual interface. All this functionality is, of course, included in the FakeFinder GitHub repository, allowing anyone with an AWS account to spin up the fully fledged FakeFinder system.
For the FakeFinder DeepFake Inference Tool, we gave users the ability to upload their video files, play them back with a set of adjustment sliders, and submit them for real/fake inference from among available models. An example usage animation is shown in the GIF below. As demonstrated here, once a video is uploaded and selected in the dropdown menu, the user can choose from the available models to submit for inference. When all results are in, their real vs. fake confidence scores (and collective score) are displayed both in a graphical representation and numerically in the model table. These are also color-coded on a blue to red scale for ease of visualization. Users can then de-select models from the list to customize the graphical output, and can then download them.
Next Steps
Looking forward, we plan to carry out user studies on FakeFinder as well as audit the models and overall system for vulnerabilities or unintended behavior. To try FakeFinder on your videos, visit our repository for instructions on how to build and use the tool. The repository also includes templates and instructions for integrating your own custom detectors. We hope that FakeFinder inspires other research groups to embed their finished models in user-friendly systems after development.

