




Photo by Lysander Yuen on Unsplash
Part 2: The Challenge and Results
Advances in deep learning, in particular generative modelling, over the past half decade have brought about a deepfake boom. Moreover, social media companies are continuously inundated with new content, and hence require an automated solution to detect manipulated or synthetic content.
The Facebook DeepFake Detection Challenge, launched at the end of 2019 during NeurIPS, invited participants to submit solutions to identify deepfake videos. In our previous post we discussed details of how the dataset was constructed, including a review of the techniques used to manipulate the actors faces and voices. In this second post we are going to focus on six submissions in particular, starting with our IQT Labs multimodal approach for deepfake detection. We will also provide additional details on the top five submissions in the competition, including the models they selected and training procedures that differentiated their approaches from others and led them to rise to the top of the competition. Stay tuned for our follow-up work incorporating these six models into a single platform, FakeFinder. We will expand on our platform in a follow up blog post, after diving into the models below.
IQT Labs
Preprocessing
Identity intelligence has been a long-standing area of interest at IQT Labs, and this DeepFake Detection Challenge motivated us to embark upon a year-long project to investigate the utility of multimodal approaches towards these types of tasks. This competition was a great place to start since we could leverage a readily available dataset to conduct initial exploratory studies.
We focused specifically on analyzing and merging features from multiple modalities in the videos within the dataset. We hypothesized that a detector built on multiple modalities would allow us to leverage information from the different input streams as well as detect deepfakes due to inconsistencies between the modalities. To work within tight timelines set by the competition, it was impractical to train the models directly on the videos, it was essential to establish a preprocessing pipeline to extract both image frames and audio from the videos, illustrated in the figure below:
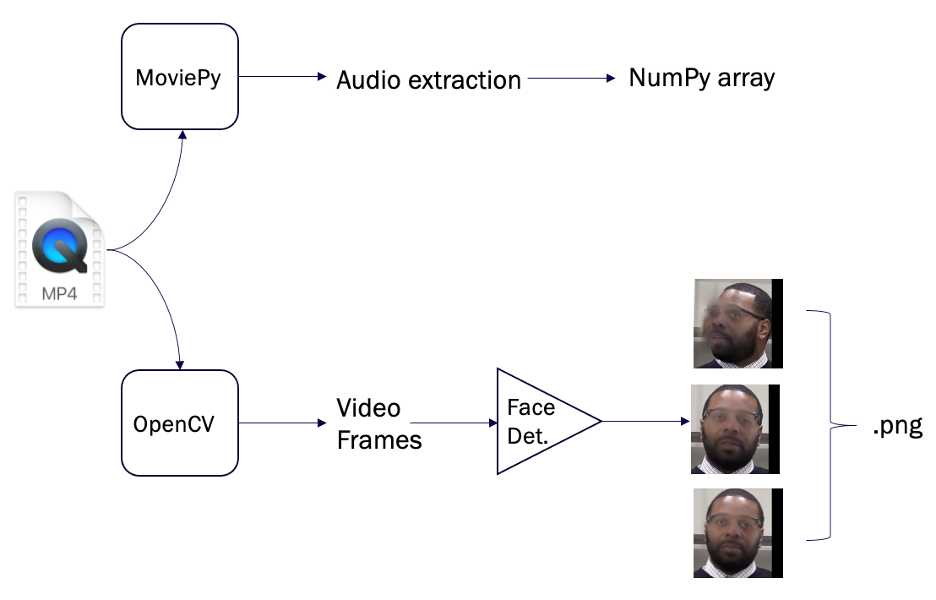
Given the strict competition requirements on the amount of time allowed to classify a video, it was unfeasible to use every frame. In order to allow our models to capture both short and long term patterns in the videos, we downsampled to 10 fps and extracted the frames from the first 3 seconds of each video. Then, we used the BlazeFace face detection algorithm to isolate the faces of the people in each frame during training. The faces were then cropped from the original frames and resized (conserving the aspect ratio) and padded to create a square image of size 224×224.

The extracted faces were then saved as uncompressed images for training and validation. A parallel preprocessing pipeline focused on the audio samples from the different videos in the dataset.
Single Frame Detection
Our initial approach focused on building a model that would distinguish real from fake using a single frame from a given video. This is an intuitive starting point, but in many cases artifacts in deepfake videos do not appear on every single frame.
Given the size of the dataset and how imbalanced it was (roughly 4:1 fake:real), we leveraged both transfer learning and external data from the downscaled Flickr-Faces Thumbnail (FF-T) dataset collected as part of training StyleGAN. Transfer learning allows us to apply state-of-the-art models that were trained on large datasets on tasks with limited examples for training. Together with the FF-T data, we selected a random face from each preprocessed video in DFDC to create a balanced real vs. fake dataset with roughly 200k images. We then applied transfer learning using a series of image classification models that had been trained using large datasets and already build powerful features for image classification.
We tested two benchmark models trained in ImageNet: VGG-19, a much deeper ResNet-152, as well as a more modern Xception network. These were compared with a model, IR-50, that had been trained specifically on face detection and facial identification included as part of the face.evoLVe library. Furthermore, in cases where data is scarce, models tend to quickly overfit, essentially memorizing the training data and failing to generalize to new examples. In these scenarios we often rely on data augmentation, applying a random set of transformations to the images during training to increase the size of the dataset. In our approach we leveraged the Albumentations package for data augmentation, including random translations, rotations, rescaling, horizontal flips, brightness and contrast shifts, motion blur, gaussian noise, and jpeg compression.
We then submitted each model against the public evaluation set, using the average prediction over the first 5 frames extracted as the prediction for the entire video.
Multi-Frame Detection
We selected our best performing, single frame detection model (Xception Net) to build off of and create a multi-frame (video) model that could account for temporal inconsistencies between frames that are introduced during the generative process. We removed the final classification layers from our pretrained Xception Net and instead fed the feature embeddings to a recurrent neural network (RNN). Our approach was motivated by related work in the area of automated action recognition, and the fact that certain artifacts from the face swapping appear in only a subset of the frames. For our specific model we selected 2 sequential Bidirectional Long-Short Term Memory units (BiLSTM) motivated by previous work on action recognition in videos. The ouput of the BiLSTMs is then followed by an attention layer and a final fully connected layer for classification. The model was then trained on 30 frames per video from our preprocessed data.
Audio Detection

Next, we focused on analyzing the audio, operating under the assumption that we might be able to detect DeepFakes given inconsistencies between the audio and video, even if the audio has not been manipulated. For our audio task, we chose to use a neural network that operates on the raw waverforms, SincNet, to potentially avoid any compression artifacts or lost information due to further preprocessing. Again, due to the relatively small dataset, we leveraged transfer learning. We first trained the SincNet on speaker identification using 100 hours of clean audio from the LibriSpeech dataset. Once trained, we transferred the model to the DeepFake detection task by replacing the final, classification layer trained on speaker identification and trained on the balanced set for deepfake detection.
Power Spectrum Detection
The last modality we explored for the competition was the image’s spatial power spectrum based on these results. The authors showed that after applying a Discrete Fourier Transform (DFT) to gray scale images and averaging over the angle there was some degree of separability between real and fake images. Following their approach, we extracted the same features from the data and trained a multilayer perceptron (MLP) to classify this 1-dimensional power spectrum as either real or fake. To train the MLP we used our same augmented DFDC + FF-T dataset, and at inference we averaged the prediction over the 30 target frames to produce a single prediction for the entire video.
Results
During the competition we added each modality (single-frame, multi-frame, audio & DFT) in turn and evaluated the contribution of each to the boost in performance. When including new modalities, we concatenated the feature embeddings from each modality and fed them through a final multi-layer perceptron consisting of two fully connected layers and ReLU activations. The next figure illustrates the final system, consisting of inputs from the multi-frame, audio and DFT detectors:
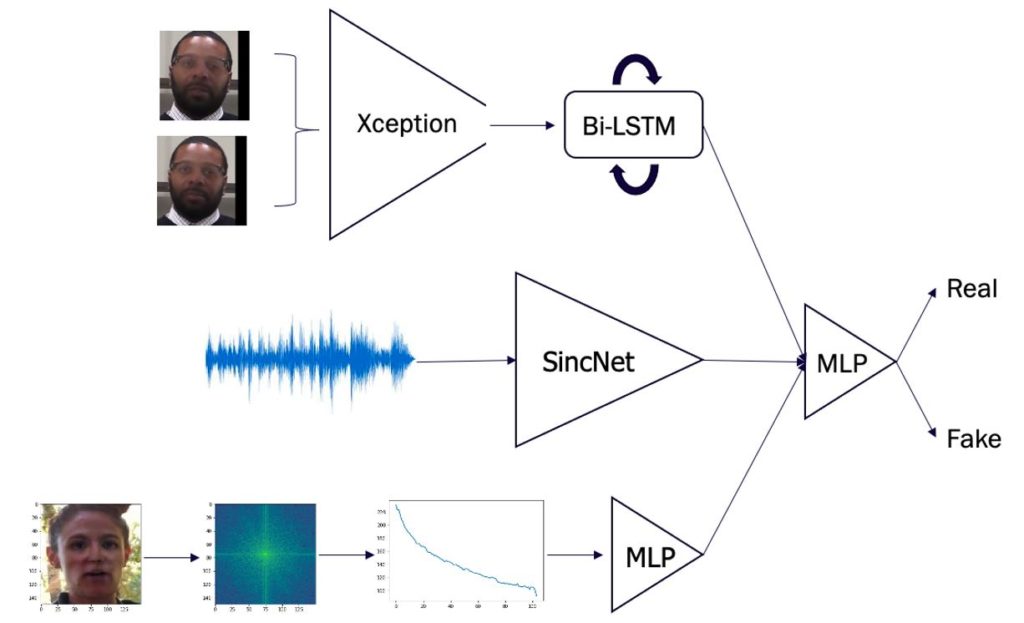
One final round of training was used for the MLP. Once trained, the models were scored against the competition. These results are shown in the following table.
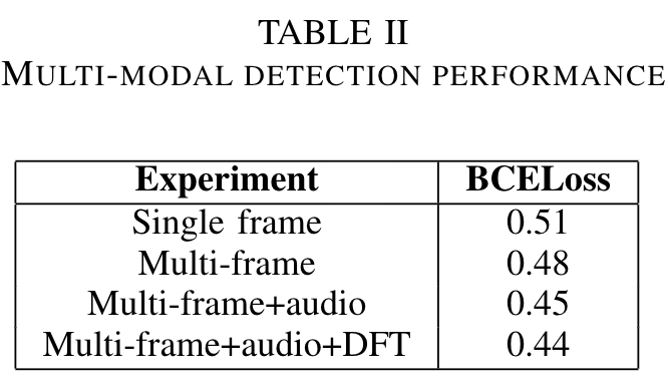
The second column indicates the Binary Cross Entropy Loss, the measure used to score and rank the submissions, where smaller is better. As we can see, the addition of each modality leads to improvement in the model performance, though the largest gains are obtained when going from single frames to video, and the addition of audio.
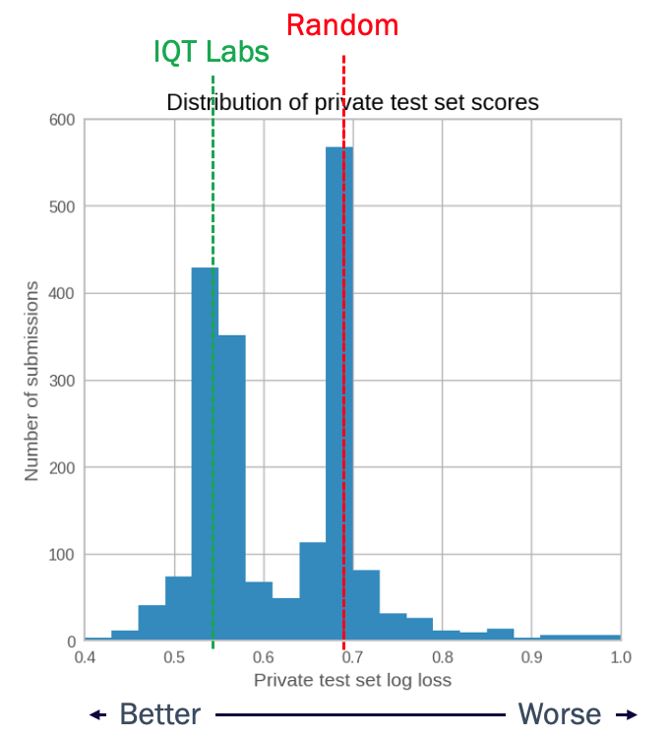
At the end of the development stage, the organizers scored the top submitted models from the participants against the larger, private evaluation dataset and re-ranked the submissions according to their performance. Most submissions, including our own, had poorer performance on this final evaluation set (our score dropped from the reported 0.44 to 0.56). Nevertheless, our own ranking dropped only a single position. The following graph shows the results of all submissions against this final evaluation set. Submissions clustered around two values: the first grouped around a loss of around 0.69 (shown by the dashed red line). This value corresponds to a simple random guess and only about 60% of the submissions did better than this. The second group clustered around a loss of 0.55-0.56, a score very similar to that of our best performing model.
Since the completion of the competition, the organizers have released details of both the dataset and large meta-analysis of the submitted solutions. We provide a brief description of the top five submissions below.
Selim Seferbekov
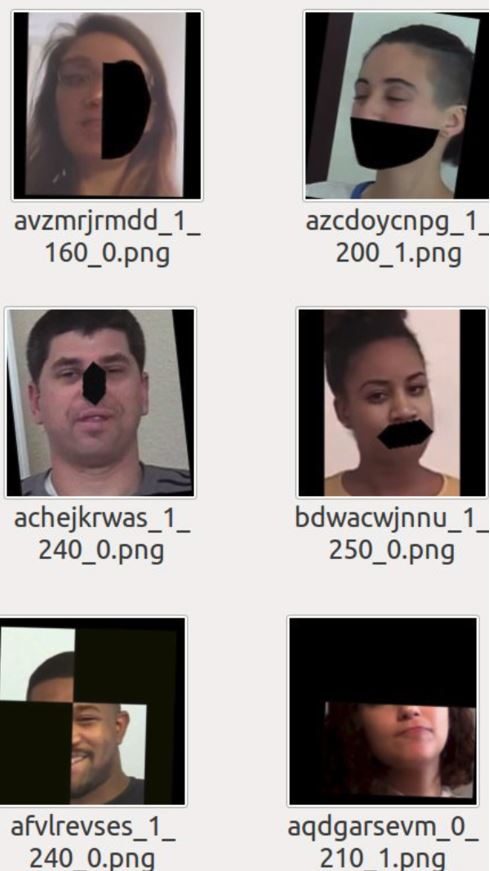
The first place submission used a different face detection algorithm MTCNN and a state-of-the-art model, EfficientNet, that was pretrained on ImageNet with a top 1% accuracy of roughly 84%. The author averaged prediction over 32 frames and used heavy data augmentations with the Albumentations package. One interesting augmentation that differentiated their approach from others involved removing either structured parts of faces (see below), or part of the images during training.
WM
Second place used the Xception architecture for frame-by-frame feature extraction. Core to their approach was the use of a second neural network for data augmentation during training, known as Weakly Supervised Data Augmentation Network (WS-DAN) which has been shown to greatly improve model generalization. The approach either crops or drops areas of images that have the highest impact on classification during training to improve the generalization.
NTechLab
Third place used an ensemble of EfficientNets, including one where 3-D convolutional blocks were added to predict on sequences of frames. An ensemble of networks was used to input different sized frames, crops and data augmentation techniques during training. In addition, the submission used mixup training where models were trained on frames that were a mix of real and fake frames: for each fake frame, the real counterpart from the original video was selected and they were combined with different relative strengths, as is shown in the following diagram.

Eighteen Years Old
Fourth place used the RetinaFace face detection algorithm and trained an ensemble of 6 different video models, including: EfficientNet, Xception, ResNet, and a SlowFast video-based network and tailored a score fusion strategy specifically for this competition.
The Medics
Fifth place also used MTCNN as the first place submission did for face detection, combined with an ensemble of seven models, largely based on the use of three 3-D Convolutional Neural Networks and two 2-D Convolutional Neural Networks. Their approach worked on at least 30 contiguous frames.
Take Aways
The DeepFake Detection Challenge provided a one of a kind dataset to study the deepfake detection problem in a realistic setting. It illustrated how challenging the task is and has showcased the power of open source to encourage experimentation and identify the most successful approaches. Though our own, multimodal approach did reasonably well, we can identify a couple of common traits amongst the winners that differed from ours and led them to rise to the top of the competition:
- All of the winners relied solely on frames from the videos, either averaging over multiple frames or relying on 3-D convolutional networks instead of RNNs.
- Many of the top performers ensembled multiple models to boost their performance.
- Their success seemed to rely more in the choices of data augmentation, than the model architecture itself.
Based on the insights that we gleaned from our research and the results of the challenge, we have continued our work on deepfake detection as part of the FakeFinder project. FakeFinder builds a modular, extensible and scalable framework for evaluating various deepfake detection models, offering a web application as well as API access for integration into existing workflows. For more information visit our repository and stay tuned for an upcoming post on our work.

